超大AI模型的高效二维张量并行
2024/7/11 14:48:02
超大AI模型近年来展现了卓越的性能,但由于硬件能力限制,我们必须使用模型并行,以分布式的方式来容纳这些无法被单个设备容纳的超大模型。目前主流的分布式AI训练系统,如微软的DeepSpeed、英伟达的Megatron均采用将模型直接划分的1维张量并行,存在冗余显存和通信效率低等问题。 针对这一痛点,Colossal-AI系统通过提供“2维张量并行”等多维张量并行,极大提升了超大AI模型的显存和通信效率,相比现有方法可提升最大模型容量或训练加速近10倍,并兼容数据并行、流水并行、序列并行、ZeRO-Offload等技术。
模型并行
为了应对超大模型对软、硬件提出的巨大挑战,研究人员提出了流水并行和张量并行,把大模型的参数分布到多个设备上进行计算。其中流水并行将模型按层结构进行分段,每个处理器从前一个处理器获得输入,再将输出结果传给下一个处理器。张量并行,如英伟达Megatron,通过将模型层内的权重参数按行或列切分到不同处理器上,利用分块矩阵乘法,将一个运算分布到多个处理器上同时进行。
英伟达Megatron的张量并行本质上使用的是1维矩阵划分,这种方法虽然将参数划分到多个处理器上,但每个处理器仍需要存储整个中间激活,在处理大模型时会浪费大量显存空间。此外,由于仅采用1维矩阵划分,在每次计算中,每个处理器都需要与其他所有处理器进行通信,因此通信成本会随并行度增高而激增。
2维张量并行
显然,1维张量并行已无法满足当前超大AI模型的需求。对此,Colossal-AI提供多维张量并行,即以2/2.5/3维方式进行张量并行。以2维张量并行为例,它通过SUMMA二维矩阵乘法,同时分布了参数和激活,实现了高效的通信和显存利用。
通信优化
假设有q×q个处理器,模型张量也都被平均划分为q×q的子矩阵分布到相应处理器上。 表示矩阵A第i行第j列的子矩阵。以计算 为例,SUMMA将矩阵乘法视为一组外积的和。将A矩阵按照列划分为 , B矩阵按照行划分为 ,其中上标表示列矩阵,下标表示行矩阵。对于外积 可以推出,第j行第k列的处理器所持有的 子矩阵为 。 , 第k列的每个处理器都需要 。
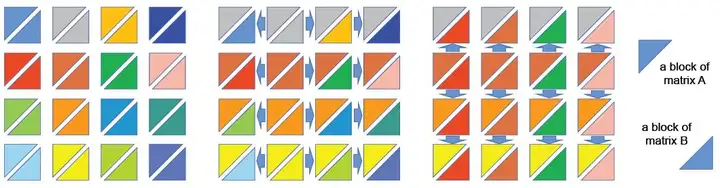
如上图所示,共有16个处理器,以i=2为例。第二列的所有处理器将自己的A子矩阵广播到同一行的每个处理器;第二行的所有处理器将自己的B子矩阵广播到同一列的每个处理器。然后,每个处理器在本地计算其持有的A和B的子矩阵相乘。
由于使用了二维网格结构,在计算超大AI模型时,相比一维结构可大幅减少通信成本。例如,对于10×10共计100个GPU而言,若使用英伟达Megatron的1维张量并行,每个GPU需要与其他99个GPU通信,则单次计算共需100×99=9900次通信。而使用2维张量并行,每个GPU仅需要与9个GPU通信,则单次计算共需100×9=900次通信,能够大幅提高通信效率。
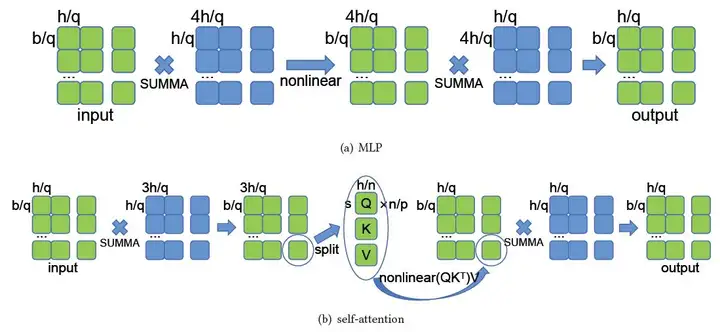
就具体实现而言,模型中多层感知机和自注意力组件的结构映射如下图所示:
显存管理
由于Transformer是由N个结构相同的Transformer layer依次叠加共同组成,这为重复利用显存空间提供了可能,即每一层中相同的计算可以使用同一块显存空间。因此,除了使用常见的activation checkpointing,我们设置了工作、正向传播、反向传播、参数梯度和连接等多种不同的缓冲区,分别存放本地子矩阵、activation和梯度等,并在不同层计算时对显存空间重复使用,极大提高了显存空间的利用率。
实验结果
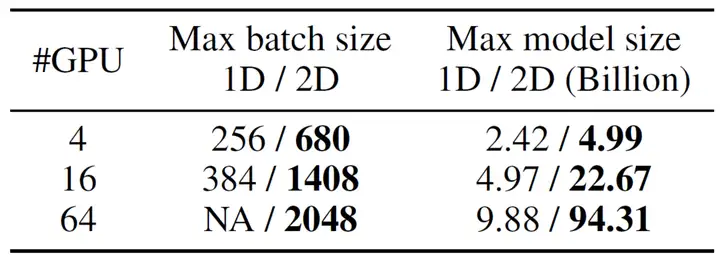
我们在64个NVIDIA A100 40GB GPU集群上,以ViT-Large/16模型为例,在ImageNet-1K数据集上进行了实验。
相比英伟达的Megatron的1维张量并行,2维张量并行可实现5.3倍的最大批处理量或9.55倍的最大模型容量。注意,由于在ViT-Large/16中仅有16个attention heads,使用1维张量并行最多将标准的ViT-Large/16扩展到16个GPU。
为了对比大规模并行时对于AI大模型的速度差异,我们将ViT-Large/16的attention heads设置为64,hidden size也设为对应的4096,此时模型参数量约为50亿。由于2维张量并行在显存利用上的优势,允许使用更大的批量大小,以及针对通信进行了优化,因此可实现9.6倍的训练加速。
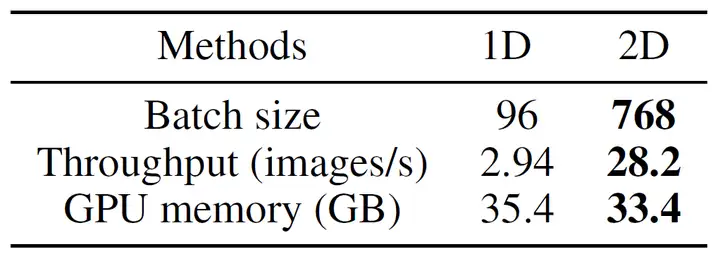
由于硬件资源限制,当前实验仅展示了64GPU的扩展性,在更大规模并行及更大模型的实验中,2维张量并行将会取得更加明显的优势。
并行维度最多
多维张量模型并行不仅性能卓越,还与已有的数据并行、流水并行、序列并行等并行模式充分兼容,共同组成了世界上并行维度最多的AI训练系统——Colossal-AI,为低成本快速训练超大AI模型提供了更好的选择。
更多特性
目前Colossal-AI系统仍处于beta测试阶段,更加惊艳的结果将会在近期发布。
我们也会根据用户反馈与既定计划,进行密集的迭代更新,尽早为用户提供正式版。

